
The rapid increase in machine learning technology across the oil and gas sector offers offshore operators the chance to automate high-cost, error-prone tasks in which the cumulative effects of inconsistency and errors in analysis can adversely impact safety.
For instance, as part of the maintenance process, it is standard practice to conduct a review of the maintenance records for each asset. This ensures operators of onshore and offshore installations are recording and trending the data for their installations correctly.
Maintenance and reliability teams currently do this by selecting a small sample of maintenance records for each safety and environmental critical element (SECE) to review. A small representative set of data is chosen as it would be too labor-intensive to manually review all records. This approach however, can lead to a sampling bias in the results. For example, inaccurate maintenance records may not be analyzed, which reduces the value of this process to the operator.
Meaningful Results
According to a recent survey by DNV GL, 49% of respondents in 2017 said that they needed to embrace digitalization to increase profitability at their organization. In 2018, that figure has increased to 70%. |
|---|
To analyze a large number of maintenance records, a potential solution is to use machine learning (ML) classification algorithms with a technique known as text mining. Verifiers can then analyze the entire set of maintenance records for each SECE on the asset. They can detect anomalies in the way that maintenance records for each SECE have been recorded, allowing the review to focus purely on records which have anomalies, as opposed to a random sample method currently used by most companies. Equally, such techniques could be utilized on any data set for which analysis is repetitive, labor-intensive, or prone to human error.
In just a few seconds, a trained ML algorithm can automatically produce a list of records with anomalies. This gives maintenance and reliability teams a more focused approach to check records by specifically targeting the anomalous maintenance records. Crucially, by reducing the amount of time spent reviewing non-erroneous maintenance records, this increases project efficiency and allows more useful findings and recommendations to be made. Using ML to carry out quality checks of data being recorded is just one application.
Improving Safety and Sustainability
The application of ML or artificial intelligence (AI) to review records and data enables operators to analyze and interpret vast amounts of data autonomously without the need to code thousands of bespoke rule sets to recognize unique patterns in data or handle exceptional circumstances. Rather effort shifts to ensuring high-quality “clean” data are used to train models.
ML algorithms have the following advantages when being used to analyze data for the oil and gas industry:
- The rate at which a machine can assess records is much faster than if done by a human, saving time and cost
- ML algorithms are less subject to human bias (except when training). The audit results are repeatable and not dependent on the person conducting the analysis
- By basing the analysis and findings on a large data set rather than a small sample size of data, the results and recommendations give a more complete picture and have more value to the operator
- By analyzing an entire data set for trends in availability and reliability, the full asset can be reviewed. This allows for root cause analysis of failures to be carried out using only maintenance logs.
AI for Auditing
Text data mining or text analytics is the process of deriving a useful “feature set” from text usually achieved by recognizing patterns in the textual data. The end goal is to turn the text available for analysis into data that are usable by a computer. There are a variety of methods for carrying out this task, but this article will focus on natural language processing (NLP) and support vector machines (SVM) with supervised ML.
NLP is used to clean up unformatted text to be reviewed by the machine. For example, this allows words or syntax, which add little or no context to the paragraphs being analyzed, to be removed or replaced. This can assist the ML algorithms to define and recognize patterns between key words more easily. While operators may not trust that the quality of their data is good enough to carry out any form of evaluation however, as part of a pilot study undertaken by DNV GL and TAQA, we demonstrated that almost all the unconstrained text data in their logs could be evaluated using NLP techniques.
To carry out supervised ML, the algorithm requires some input data to learn from. This “training data” enables the model to make all future comparisons and assessments.
Worked Example
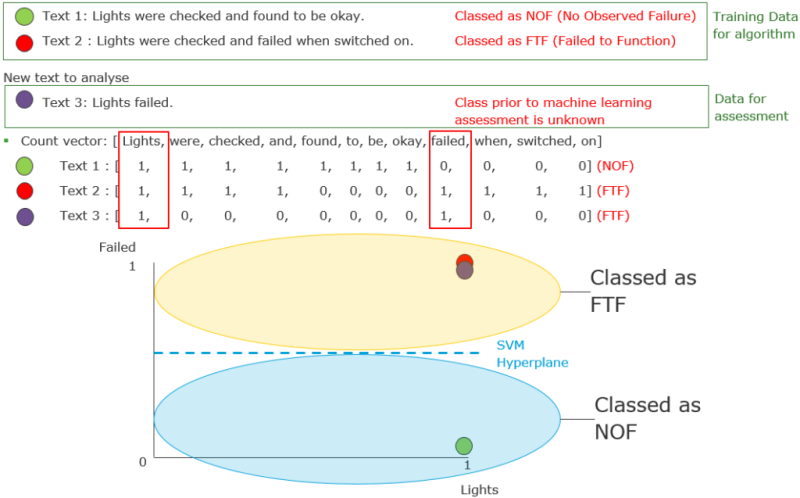
In Fig. 1, Text 1 ‘lights were checked and found to be okay,’ and Text 2 ‘lights were checked and failed when switched on’, shows an example of two possible training data sets which can be used to assess the functionality of a lighting circuit.
Text 1 has been manually labeled or classed as having no observed failure (NOF), while Text 2 is labeled as failing to function (FTF). This supervised training data can be visualised as either in a count vector format (a series of numbers counting the occurrences of each word), or as points on a graph spanning across multidimensions. A boundary SVM hyperplane is setup automatically to distinguish between the different labels being used for the training data.
As illustrated in Fig. 1, when the ML algorithm is given a new unlabeled text, Text 3 ‘lights failed,’ the algorithm compares the features of this text phase to the features of the phases used in the training data. This plot shows two dimensions only for illustration; in reality the “hyperplane” may have more dimensions. The phrase ‘lights failed,’ has features more in common with Text 2, so the machine can automatically determine that this is a “failing to function” description rather than an item where “no failure is observed.”
This simple technique allows verification engineers and maintenance and reliability teams to assess large amounts of maintenance data rapidly and identify failure records of SECEs instantly, even if the maintenance log for the item itself has never been flagged as failure. This independent ML check also allows engineers to detect problems in the way records were tagged.
For example, if the maintenance log for an item has been marked to state that the item is working correctly, but upon closer inspection the text description of the field describes a failure, the ML algorithm can detect this and report it to the teams for further findings to be raised. The ability of ML algorithms to interrogate data on a vast scale allows teams to detect small-scale problems quickly and correct them before the issues accumulate and impact the safety or operability of an asset.
In reality, different maintenance engineers on different assets will describe their maintenance log in a variety of ways using a diverse range of linguistics. This is where textual analysis done using a combination of NLP and ML can succeed where previous key word finders and other analysis types would have failed. As long as the training data contain the example linguistics used by the engineers, the algorithms can label these. As the name suggests, “learning” algorithms can learn and be improved with time. This makes them more robust and able to adapt to the variety of words used in maintenance record logs.
Other processes that can be automated in this way include:
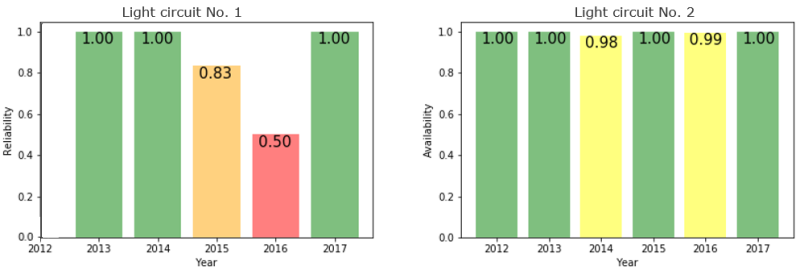
- The ability to trend (and potentially predict) availability and reliability data for assets based purely on textual analysis, as shown in Fig. 2
- Root cause analysis of failures and worst case offenders on the asset to determine what is driving failures and downtime
- Identifying anomalies in data being recorded, to determine if inspection and maintenance activities have been incorrectly prioritized, which may lead to items being inappropriately risk-assessed
- Deferred maintenance reviews
- Alert staff to increased major accident hazard potential or occupational safety risks
Outcomes and Benefits
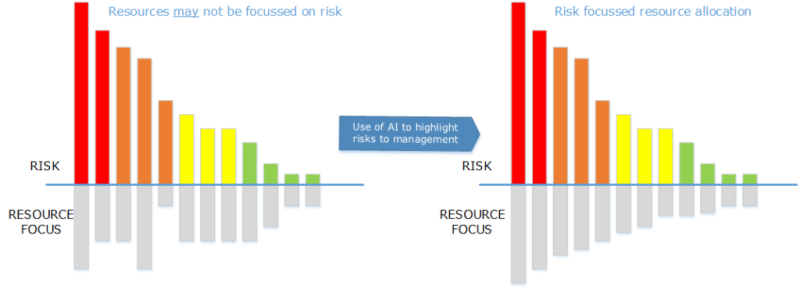
AI can assess and classify huge amounts of data in seconds. This allows tasks that were previously impossible to be made possible. The benefit of this is a more robust, unbiased understanding of the risks and vulnerabilities of assets.
By being more informed about the problems and reliabilities of equipment, better decisions about maintenance and safety tasks can be made. The result is less time wasted analyzing and evaluating low-risk items with no anomalies to report, and by focusing attention on high-risk items where anomalies are detected and should be corrected (Fig. 3).
Implementing AI
Today’s increased focus on digitalization is linked to the oil and gas industry’s drive toward greater cost efficiency. According to a recent survey by DNV GL, 49% of respondents in 2017 said that they needed to embrace digitalization to increase profitability at their organization. In 2018, that figure has increased to 70%.
“Confidence and Control: The Outlook for the Oil and Gas Industry in 2018” is DNV GL’s eighth annual report providing a snapshot of industry confidence, priorities and concerns for the year ahead. It reveals an imminent turnaround in spending on R&D and innovation after 3 years of cuts and freezes. More than a third (36%) of 813 senior sector players surveyed expect to increase spending on R&D and innovation in 2018: the highest level recorded in 4 years. Digitalization (37%) and cybersecurity (36%) will form the principal areas of R&D investment focus this year.
To benefit fully from the implementation of AI, operators with successful programs must think in terms of total life cycle costs and economics and should build teams that will benefit from the application of such technology. The successful implementation of “learning” algorithms requires good training data. Regardless the models are not 100% accurate; they can still return false-positive or false-negatives results, for example. This means the process is not fully automated as competent engineers are still required to train the algorithms and validate the results. But within these constraints, we can still greatly improve over traditional random sampling methods.

Chris Bell is a chartered engineer with the IMechE, and has a PhD in material science research and a masters in physics and applied mathematics. Chris has over 10 years engineering/R&D experience particularly focused on projects using new methods, materials and/or equipment. He has experience with the planning, designing, manufacturing, and the analytical stages of developing new technologies, and a safety/risk and asset integrity background as well as a proven track record of programming and developing unique digital solution for customers.