
We are currently experiencing a wave of disruptive technologies centered around recent advancements in artificial intelligence (AI), internet of things, big data, robotics, nanotechnology, advanced materials, and 3D/4D printing. Welcome on board the Fourth Industrial Revolution (4IR).
Until now we have gone through three such revolutions. The first was the introduction of steam power at the end of the 18th century that mechanized production. The second comprised the widespread development of electricity at the beginning of the 20th century that allowed mass production. The third was the advent of information technology (IT) in the 1970s that introduced automated production. The fourth one builds on the infrastructure provided by the third revolution to launch us into the wave we are currently experiencing.
The impact of the 4IR is massive as it integrates several disruptive technologies. It is already affecting our personal lives and is set to completely transform the petroleum industry business.
Recent articles (Robinson, 2018; Ighalo et al., 2018) give a high level insight into the importance of utilizing the massive amount of data available in the petroleum industry today and building data analytics capabilities around the evolution of IT infrastructure. Even though AI has been applied in other fields for more than 4 decades, its application in the petroleum industry has been sparse and limited.
This article will give a succinct overview of the AI paradigm, discuss the challenges in applying AI in the petroleum industry, highlight some of the emerging opportunities and prospects, and conclude with recommendations to accelerate the admission of AI into workflows.
AI 101 |
|---|
My favorite definition for AI is the one proposed by a Stanford University Professor, John McCarthy: “The science and engineering of making intelligent systems.” It should be known that those “intelligent systems” could be hardware (e.g., robotic arms during some repetitive jobs like capping drink bottles), software (e.g., algorithms that recognize patterns), or a combination of both (e.g., autonomous rovers that make independent decisions based on certain events).
AI could not have existed without computers. Therefore, the discussion on the history of AI would not be complete without looking at the history of computers. Some computer-like developments started as early as 1800. The first electronic computer, ENIAC, was developed in the early 1940s. This facilitated the arrival of the first commercially stored program later in the decade around 1949. With this success, more programming languages were rolled out in quick succession: LISP language in mid-1950s followed by PROLOG in early 1970s, when the first expert system was revealed. With this strong foundation, more advanced programming languages have evolved over time and continue to the present day.
The words “artificial intelligence” were first mentioned at a conference in 1956. Leveraging the capability to program computers, the new field of AI rapidly developed. This assisted the development of Artificial Neural Networks (ANN) along with other variants such as Generalized Regression Neural Networks, Radial Basis Function Neural Networks, Probabilistic Neural Networks, and Cascaded Neural Networks. AI became a multi-million dollar business with the introduction of AI-based hardware in 1986 and started to be incorporated in military systems and games in the early 1990s.
The news of an AI machine (Deep Blue) beating a human chessmaster (Garry Kasparov) came in 1997. There was a massive launch of AI-based products, both software and hardware, by companies such as Apple, Google, and Microsoft from 2010. Advanced machine learning (ML) concepts such as hybrids, ensembles, and deep learning followed rapidly to accelerate the application of automatic image classification and object recognition using Convolutional Neural Networks. Since the middle of this decade, extensive deep learning applications have been developed and actively supported by improved and advanced hardware capabilities to handle the complexities of the applications.
The next section attempts to clear the confusion around the terms data science, computational intelligence, AI, and neural networks.
Clearing the Confusion |
|---|
People outside the data science community have used the terms: data science, computational intelligence, AI, and neural networks, interchangeably. AI is not a “technique.” It is a branch of computer science that covers other sub-fields such as Natural Language Processing, Expert Systems, Robotics, and Computational Intelligence. CI, also known as soft computing or neural computing, combines knowledge discovery (KD), pattern recognition, and data mining processes to develop ML workflows.
Some of the various techniques that can be used for ML are ANN and its variants, Decision Tress, Random Forest, Support Vector Machines, Extreme Learning Machine, Fuzzy Logic Types I and II, Adaptive Neuro-Fuzzy Inference System (popularly mentioned in the literature by its abbreviation ANFIS), and Nearest Neighbors. This new and rapidly evolving field that uses various scientific methods, processes, algorithms, and systems to extract knowledge or insights from data in various forms, either structured or unstructured, is called data science.
It is also necessary to clarify the relationship among KD, data mining, and ML.
Knowledge Discovery, Data Mining, and Machine Learning |
|---|
The KD process is a collection of tasks and procedures that are used to extract knowledge or meaningful insight from data. It starts with identifying a challenge.
The type of challenge determines the data to use. This is the data selection phase. For example, if you need to predict reservoir porosity, you would need petrophysical data, among others, rather than geochemical. The selected data usually needs to be preprocessed to remove anomalies, outliers, noise, and other artifacts. Based on the statistical evaluation of the selected data, it might be necessary to apply some transformation functions such as log normalization or resampling on the data. This is the point data mining comes in.
The most common among the possible data mining techniques is ML (discussed below). The result of data mining is a recognized pattern. The pattern will be interpreted, evaluated, and validated to generate a new insight that can be added to the organizational workflow. The KD process is summarized in Fig 1.
Overview of Machine Learning |
|---|
The main tool used for data mining is ML. In simple terms, ML can be defined as the process of teaching computers to do what humans naturally do without being explicitly programmed. Through ML, algorithms are able to continuously learn from historical events captured in data and adaptively improve their predictive capabilities with more data.
There are three ML methods: supervised, unsupervised, and hybrid learning. Supervised ML algorithms learn patterns from historical examples. This is called training. The trained model is able to predict the target variable given new input instances. An example is to use the relationship between wireline logs and reservoir properties from historical data to predict the properties of a new reservoir given new input scenarios. Typical applications of this learning method are regression and classification.
Unsupervised ML algorithms make inferences from events depicted by data without prior classification or label. They infer a function, usually based on some distance metrics, to describe a hidden structure from unlabeled data. From this result, an expert can derive meanings that can lead to new insights.
An example is to use historical log data to compartmentalize a reservoir into sections based on certain signatures such as the density of data points. An expert may then interpret the sections as different lithologies. A typical application of this learning method is clustering.
Hybrid ML algorithms combine supervised and unsupervised methods to arrive at a solution in situations where there are uncertainties in human knowledge. They have the capability to considerably improve learning accuracy with limited labels. An example of this is to use a clustering approach to compartmentalize a huge volume of reservoir data into sizeable zones before applying regression or classification.
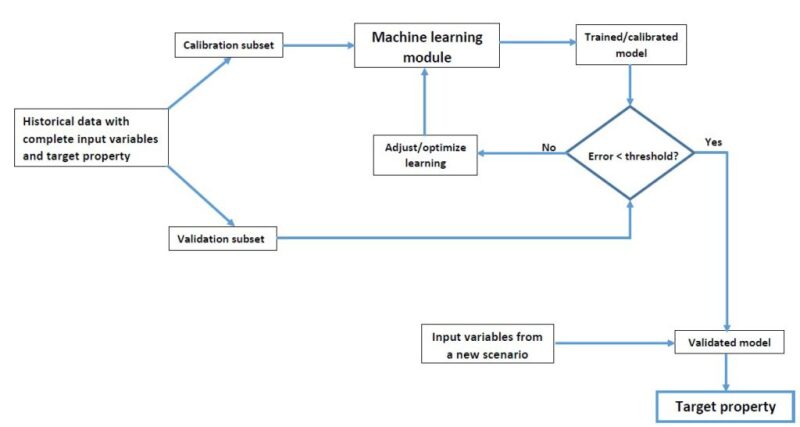
In summary, ML enables analysis of massive quantities of data. While it generally delivers faster and more accurate results to identify profitable opportunities or dangerous risks, it may also require considerable amount of time and resources to train it properly. The main objective of ML is to maintain a balance between underfitting and overfitting. The traditional ML workflow is shown in Fig 2.
When To Use Machine Learning? |
|---|
At this point, I am sure that readers would begin to wonder about when to use ML. The following guidelines are helpful:
No existing rule/equation. If there is an established relationship among certain parameters that can be accurately defined by an equation, then there is no need for ML. For example, we know that the distance traveled is directly proportional to speed and inversely to time. This is universally established. Using ML to predict distance from speed and time will be useless. Investigating the relationship between log measurements and reservoir permeability would be a good candidate for ML.
Rules and equations are too complex. When a set of rules or an equation is based on very complex and confusing assumptions, then consider using ML.
Rules are constantly changing. When relationships change due to various conditions, then consider using ML. For example, when some relationships that are valid for clastic reservoirs become invalid in carbonates, then ML can be used to derive a complex relationship in both environments.
The nature of data keeps changing. If the nature of data keeps changing such that the fundamental principles of the underlying equations are no more honored, then ML might be useful to establish a nonlinear dynamic mapping to handle the change.
Large amount of data. Small datasets can be modeled easily using basic statistical functions. As data volume increases, ML may become necessary. This is the reason AI has now become synonymous with “big data.”
Challenges and Limitations of Machine Learning |
|---|
ML has been around for more than 4 decades, but until recently, not much progress has been made in its adoption in the oil and gas industry. The applications have been isolated and sparse. The following could be the reasons:
It requires substantial data. Having access to large enough historical dataset to ensure effective model training and generalization capability has been a major challenge.
Poor quality data. Even when some data are available in sufficient volume, the quality may be questionable. Poor quality data produces poor quality predictions. This will remind us of the “garbage in, garbage out” maxim. Dr. Pedro Domingo of the University of Washington said “Machine learning can’t get something from nothing … what it does is get more from less.”
The learning process requires a degree of expertise. Most users of ML in the industry simply go with the default parameter settings in those packages. ML is an art in itself and hence needs to be mastered. It goes beyond simply running the ANN app over a dataset. There are technicalities involved in choosing the right features, tuning the model parameters, trying different learning algorithms and activation functions, and possibly carrying out certain post-processing activities to enhance the output and presentation of the process.
Focus on pattern in data rather than the physics of the problem. One of the possible reasons petroleum industry experts would not easily accept the ML paradigm is the focus of the latter on extracting patterns in data rather than incorporating the physics of the problem. This will continue to pose a challenge until there is a very close collaboration between data scientists and domain experts to leverage the strength of both parties.
Recommendations for Successful Application in Oil and Gas |
|---|
Given the challenges outlined above, below are a few tips and recommended best practices for successfully adopting ML in the petroleum industry. I hope this will help avoid some of the common pitfalls that organizations and ambitious users might be vulnerable to while starting their ML-driven projects. :
Spend enough time on data quality assurance. Given the robustness of the model, good data determines the quality of the results. Most of the time when algorithms don’t perform well, it is due to a problem with the training data such as insufficient amount, skewed data, noisy data, or insufficient features describing the data for making decisions.
Choose the right features that describe the problem to be solved. This process is domain-specific and hence should be done in close collaboration with domain experts rather than being left completely to data scientists.
Seek to understand ML techniques rather than using them as black boxes. Each ML technique has its own science forming the foundation.
Make the products of ML projects easy to use. Invest enough time to build user-friendly and simple user interfaces. A process that can be executed in a few clicks is better and will be easily adopted by consumers than those that are complicated.
Build integrated solutions to form a suite. Rather than building ML applications around small and narrow problems, think of a “one-stop shop” type solutions.
Invest time in learning. When a MLalgorithm is not working, we often feed the machine with more data. This can lead to issues with scalability, in which we have more data but not enough time to invest in the “learning” process.
ML is not a magic wand. It may not be able to solve all problems. Handle ML projects with a focus on clear set of objectives driven by knowledge of the possibilities and limitations of the ML paradigm. Attempting to use it as a blanket solution that must work in all situations seldom works.
This article has been written with the objective of providing a basic understanding of AI, its relevant terminology, and the rudiments of how it works. I hope that I have succeeded in infusing the “AI thinking” in the minds of the readers and tickled your interest in looking for opportunities to apply ML in your projects.
References
Robinson, D. (2018) What's the Difference between Data Science, Machine Learning, and Artificial Intelligence? The Way Ahead.
Ighalo, S., Blaney, J., and Sachdeva, J.S. (2018) Keeping up with the Digital Age: What is Data Analytics all about? The Way Ahead.

Fatai Anifowose is a research scientist at the Geology Technology Division of the Exploration and Petroleum Engineering Center, Advanced Research Center in Saudi Aramco. His career interweaves the artificial intelligence aspect of computer science with reservoir characterization aspect of petroleum geology. His expertise is in the application of machine learning and advanced data mining in petroleum reservoir characterization. Anifowose has published more than 45 technical papers in conferences and journals. He is a member of SPE; European Association of Geoscientists and Engineers; and Dhahran Geoscience Society, Saudi Arabia. Anifowose obtained his PhD degree from the University of Malaysia, Sarawak, in 2014; MS from King Fahd University of Petroleum and Minerals, Saudi Arabia, in 2009; and BTech from the Federal University of Technology, Akure, Nigeria, in 1999.
