
Introduction
A lot has been written about artificial intelligence (AI) technology and how it relates to machine learning (ML). In a previous article, I discussed the basic principles of AI, including the traditional ML technology, in very simple terms in the context of the Fourth Industrial Revolution and its associated disruptive technologies. The article gave a succinct overview of AI, discussed the challenges in applying AI in the petroleum industry, highlighted some of the emerging opportunities and prospects, and concluded with recommendations to accelerate the admission of AI into the regular petroleum industry work flows.
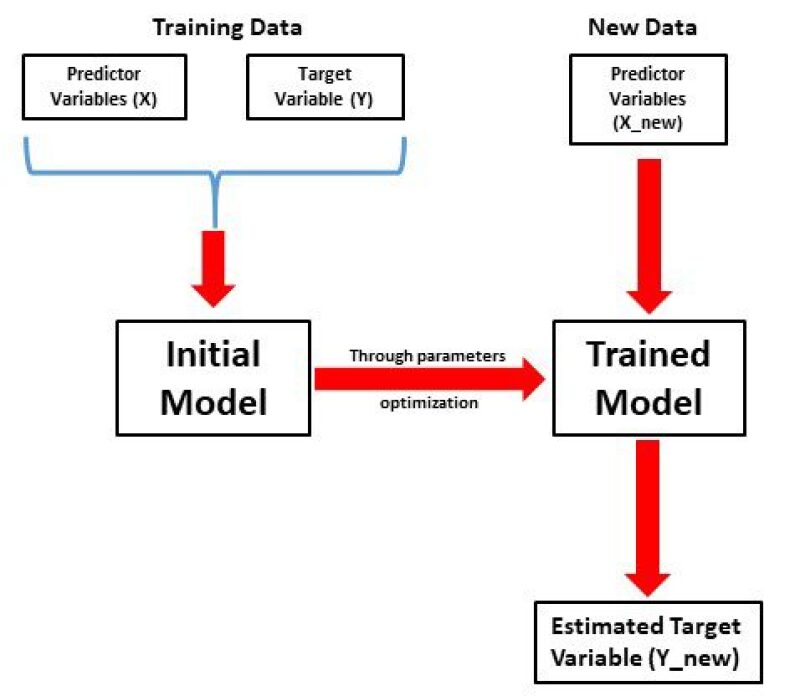
As a recap, AI is a subfield of computer science that focuses on the design and development of intelligent systems in the form of hardware, software, or both. AI is the umbrella technology that encompasses various advancements and areas of application such as robotics, natural-language processing, expert systems, and ML. ML is the computational aspect of AI that uses the processes of knowledge discovery, pattern recognition, and data mining to learn automatically from data and develop predictive work flows. The conventional supervised ML method consists of presenting input data (predictor and target variables) to a trained model. The training process seeks to identify through an iterative procedure a set of model parameters that maximizes the relationship between the predictor (input features) and the target variables. The trained model receives new input data for the predictor variables and uses the recognized pattern to estimate the target variable. Fig. 1 shows a simplified schematic of this work flow.
Most of the ML methods used today follow this work flow. Examples of such methods are artificial neural network (ANN), decision tree, and support vector machine (SVM). This work flow has been in use for more than 4 decades. A new ML work flow that advances the traditional approach is hybrid ML (HML).
In the context of understanding the ML tools that we use, this new learning work flow needs to be explained. Knowing what goes into the algorithms is essential to understanding how they work. The more we understand how they work, the more transparent they look and the more we reduce the “black box” phenomenon that has been wrapped around them.
What is Hybrid Machine Learning?
Most of us have probably been using HML algorithms in one form or another without realizing it. We might have used methods that are a combination of existing ones or combined with methods that are imported from other fields. We sometimes apply data transformation methods such as principal component analysis (PCA) or simple linear correlation analysis on our data before passing them to an ML method. Some practitioners use evolutionary algorithms to automate the optimization of the parameters of existing ML methods. HML algorithms are based on an ML architecture that is slightly different from the conventional work flow. We seem to have taken the ML algorithms for granted as we simply use them off the shelf, usually without considering the details of how things fit together.
HML is an advancement of the ML work flow that seamlessly combines different algorithms, processes, or procedures from similar or different domains of knowledge or areas of application with the objective of complementing each other. As no single cap fits all heads, no single ML method is applicable to all problems. Some methods are good in handling noisy data but may not be capable of handling high-dimensional input space. Some others may scale pretty well on high-dimensional input space but may not be capable of handling sparse data. These conditions are a good premise to apply HML to complement the candidate methods and use one to overcome the weakness of the others. Fig. 2 shows a conceptual framework of the HML work flow.
The possibilities for the hybridization of traditional ML methods are endless, and this can be done for every single one to build new hybrid models in different ways. For simplicity, this article will discuss three of them: architectural integration, data manipulation, and model parameters optimization.

HML Based on Architectural Integration
This type of HML seamlessly combines the architecture of two or more conventional algorithms, wholly or partly, in a complementary manner to evolve a more-robust standalone algorithm. The most commonly used example is adaptive neuro-fuzzy inference system (ANFIS). ANFIS has been used over time and is usually thought of as a standalone traditional ML method. It actually is a combination of the principles of fuzzy logic and ANN. As shown in Fig. 3, the architecture of ANFIS is composed of five layers. The first three are taken from fuzzy logic, while the remaining two are from ANN. More technical details about ANFIS, and especially the role of each layer, can be found in Anifowose et al. (2013).

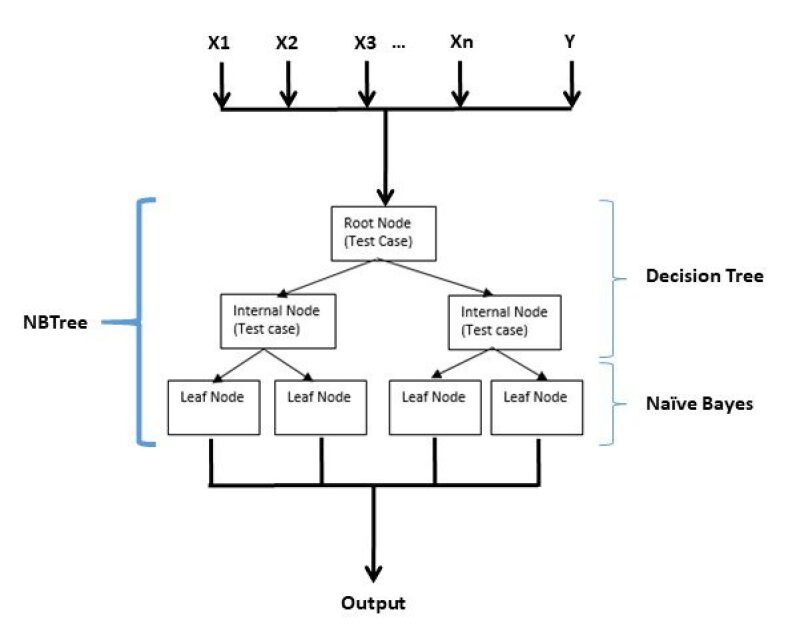
Another example of an HML method based on architectural integration is the naïve Bayes tree, or NBTree. As illustrated in Fig. 4, it is a combination of the naïve Bayes and decision tree algorithms. The decision tree nodes contain univariate splits like the regular decision tree, but the leaves contain naïve Bayesian classifiers (Kohavi 1996). The latter was essentially used to overcome the shortcomings of the former. The study noted that the performance of the naïve Bayes algorithm is excellent; however, it does not scale up nicely with higher-dimensional data. On the contrary, decision trees have the capability to scale up easily in the same condition, but they are prone to overfitting. A hybrid of these two methods became necessary to benefit from the complementary qualities of the two methods.
HML Based on Data Manipulation
This type of hybrid learning seamlessly combines data manipulation processes or procedures with traditional ML methods with the objective of complementing the latter with the output of the former. The following examples are valid possibilities for this type of hybrid learning method:
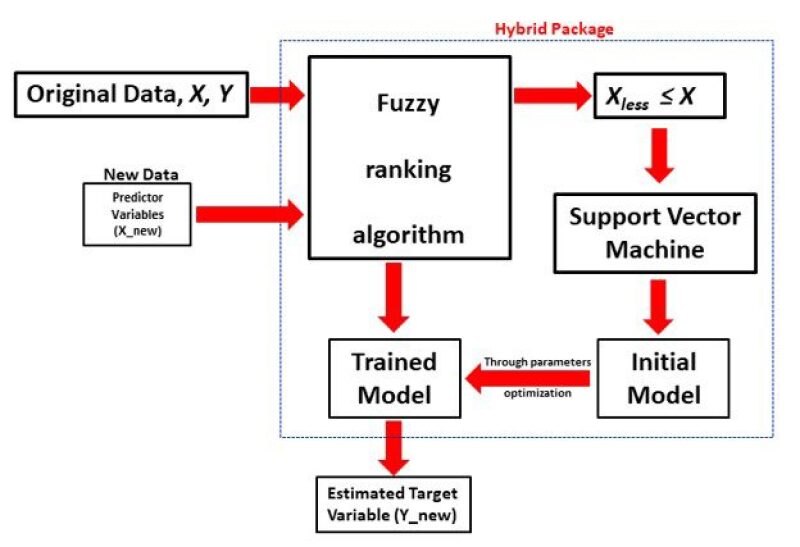
- If a fuzzy ranking (FR) algorithm is used to rank and preselect optimal features before applying the support vector machine (SVM) algorithm on the data, this can be called an FR-SVM hybrid model (Fig. 5).
- If a PCA module is used to extract a submatrix of data that is sufficient to explain the original data before applying a neural network on the data, we can call it a PCA-ANN hybrid model.
- If a singular value decomposition (SVD) algorithm is used to reduce the dimensionality of a data set before applying an extreme learning machine (ELM) model, then we can call it an SVD-ELM hybrid model.
- The fuzzy logic method can be seen as a hybrid method if the fuzzification and defuzzification processes that come before and after the inference engine are respectively seen as kinds of preprocessing and post-processing tasks that are seamlessly integrated with the inference engine.
Hybrid methods that are based on feature selection, a type of data manipulation process that seeks to complement the built-in model selection process of traditional ML methods, have become common. It is known that each ML algorithm has a way of selecting the best model based on an optimal set of input features. Consequently, recent research (Anifowose et al. 2014; Sasikala 2016) have suggested that performing this procedure using an external algorithm as a preprocessing step helps to complement the internal process by reducing the computational complexity, thereby increasing the accuracy of traditional ML algorithms.
HML Based on Model Parameters Optimization
It is known that each traditional ML method uses a certain optimization or search algorithm such as gradient descent or grid search to determine its optimal tuning parameters. This type of hybrid learning seeks to complement or sometimes replace the built-in parameter optimization method by using certain advanced methods that are based on evolutionary algorithms. The possibilities are also endless here. Examples of such possibilities are:
- If the particle swam optimization (PSO) algorithm is used to optimize the training parameters of an ANN model, the latter becomes a PSO-ANN hybrid method.
- When genetic algorithm (GA) is used to optimize the training parameters of the ANFIS method, the latter becomes a GANFIS hybrid model.
- The same goes with other evolutionary optimization algorithms such as Bee, Ant, Bat, and Fish Colony that are combined with traditional ML methods to form their corresponding hybrid models.
Example Use Cases of HML
A typical example of the feature selection-based HML is the estimation of a certain reservoir property such as porosity using integrated rock physics, geological, drilling, and petrophysical data sets. There could be more than 30 input features from the combined data sets. It will be a good learning exercise and a contribution to the body of knowledge to produce a ranking and determine the relative importance of the features. Using the top five or 10, for example, may produce similar results and thereby reduce the computational complexity of the proposed model. It may also help domain experts to focus on the fewer features instead of the full set of logs, the majority of which may be redundant.
Another possible application of this hybrid method is the determination of reservoir fluid types using the measured organic (including light and heavy) and inorganic gases liberated from the wellbore during drilling. The mud log data comprising these gases could contain up to 50 logs. In a situation of data sparsity such as what is obtained from a small hydrocarbon-producing field, using a feature selection algorithm to rank the logs and select a much smaller subset will enhance model performance and avoid possible overfitting.
Conclusion
HML methods have become common in recent applications. We have probably been using some of them without realizing it. It is, however, necessary to know about them in the context of understanding the underlying concepts of their methods and how they work. I hope this article will encourage young professionals and other ML enthusiasts to be equipped with the basic knowledge of how to build their own hybrid models using any of the strategies such as architectural integration, data manipulation, and model parameters optimization or any other relevant ones.
Suggested Additional Reading
Anifowose, F., Labadin, J., and Abdulraheem, A. 2016. Hybrid Intelligent Systems in Petroleum Reservoir Characterization and Modeling: The Journey So Far and the Challenges Ahead, J. of Pet. Exploration and Production Tech. 7: 251–263.
Azeem, M.F., Hanmandlu, M., and Ahmad, N. 2000. Generalization of Adaptive Neuro-Fuzzy Inference Systems, IEEE Transactions on Neural Networks, 11 (6): 1,332–1,346.
Jang, J.R. 1993. ANFIS: Adaptive Network-Based Fuzzy Inference System, IEEE Trans. on Systems, Man and Cybernetics, 23 (3): 665–685.
References
Anifowose, F. 2019. Artificial Intelligence Explained for Non-Computer Scientists, The Way Ahead.
Anifowose, F.A., Labadin, J., and Abdulraheem, A. 2013. Prediction of Petroleum Reservoir Properties Using Different Versions of Adaptive Neuro-Fuzzy Inference System Hybrid Models. Inter. J. of Computer Information Systems and Industrial Management Applications 5: 413–426.
Anifowose, F., Labadin, J., and Abdulraheem, A. 2014. Nonlinear Feature Selection-Based Hybrid Computational Intelligence Models for Improved Natural Gas Reservoir Characterization. J. of Natural Gas Science and Engineering 21: 397–401.
Kohavi, R. 1996. Scaling up the Accuracy of Naïve-Bayes Classifiers: A Decision-Tree Hybrid. Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, pp. 202–207.
Sasikala, S., Balamurugan, S.A., and Geetha, S. 2016. Multi-Filtration Feature Selection (MFFS) To Improve Discriminatory Ability in Clinical Data Set. Applied Computing and Informatics 12 (2): 117–127.

